

In a dimly lit data center, the hum of thousands of GPUs reverberates through the room, each one tirelessly churning through data. This is the heartbeat of modern artificial intelligence. And it’s here, amidst racks of machines glowing with the flicker of activity, that a technological marvel — LLaMA 3.1 — was born. When you interact with a cutting-edge language model, it feels magical. Its responses are precise, sometimes eerily human. But what most don’t realize is that behind every seemingly effortless answer lies a Herculean effort, involving staggering computational power, immense datasets, and millions of dollars. This is the untold story of training LLaMA 3.1, a journey into the depths of engineering, mathematics, and logistics.
In a dimly lit data center, the hum of thousands of GPUs reverberates through the room, each one tirelessly churning through data. This is the heartbeat of modern artificial intelligence. And it’s here, amidst racks of machines glowing with the flicker of activity, that a technological marvel — LLaMA 3.1 — was born.
When you interact with a cutting-edge language model, it feels magical. Its responses are precise, sometimes eerily human. But what most don’t realize is that behind every seemingly effortless answer lies a Herculean effort, involving staggering computational power, immense datasets, and millions of dollars. This is the untold story of training LLaMA 3.1, a journey into the depths of engineering, mathematics, and logistics.
A Model of Epic Proportions
Imagine trying to teach a child everything there is to know about the world — language, reasoning, problem-solving — using not just textbooks, but the entire Internet. That’s essentially what goes into training a model like LLaMA 3.1. Here are the raw numbers:
- 405 billion parameters: These are the trainable knobs and dials of the model, the variables that allow it to “learn” from data.
- 15.6 trillion tokens: The digital equivalent of sentences, paragraphs, and books, representing the vast ocean of knowledge fed into the model.
- Compute optimality: Efficiency measured as the number of tokens processed per parameter. For LLaMA 3.1, it is 40 tokens per parameter.
- TFLOPS: Trillions of Floating Point Operations Per Second (10 power 12 FLOPs per second).
Training a model of this scale isn’t just difficult — it’s monumental. Each parameter must be adjusted repeatedly based on the tokens it processes, requiring billions of mathematical operations every second.
What Are FLOPs, and Why Do They Matter?
To understand the sheer magnitude of this task, we need to talk about FLOPs — **Floating Point Operations Per Second. ** FLOPs measure the computational effort required for training machine learning models.
For LLaMA 3.1, the total FLOPs required can be calculated using this formula:
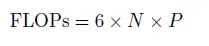
Where:
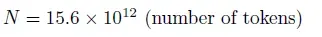
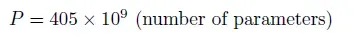
- The constant 6, which accounts for all stages of training: the forward pass, backward pass, and optimization.
Substituting these values, the total FLOPs become:
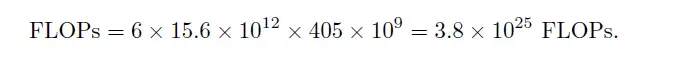
To put this into perspective, that’s 38 septillion operations — 38 followed by 24 zeros.
Stages of Model Training
Training a model involves three critical stages, each contributing to the computational load:
-
Forward Pass: This is the “thinking” phase where the model processes input data to make predictions. It accounts for : 1×N×P
-
Backward Pass: Here, the model learns from its mistakes, calculating gradients to update its parameters. This stage is twice as computationally intensive, contributing : 2×N×P
-
Optimization: Finally, the model updates its parameters based on the gradients, adding another : 1×N×P
Together, these stages require 4×N×P FLOPs. The additional overhead from memory management and activation storage increases the multiplier to 6, making it a reliable estimate for modern deep learning workloads. Hence the value : 6×N×P
The Powerhouse Behind LLaMA 3.1
To handle such an astronomical number of calculations, researchers turned to one of the most advanced hardware setups ever assembled:
- 16,000 NVIDIA H100 GPUs, each capable of delivering 400 TFLOPS (trillions of floating-point operations per second).
- A custom-built data pipeline optimized to feed data into GPUs at breakneck speed.
Training the model took 70 days of continuous operation, with every GPU running at full capacity, consuming energy equivalent to powering a small town.
The Price of Intelligence
Training an AI model isn’t just a computational challenge — it’s a financial one too. Here’s a breakdown of the costs:
- Compute Costs Renting GPUs for training costs approximately $2 per GPU hour. Over 70 days, the total GPU hours amounted to:
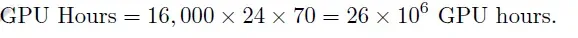
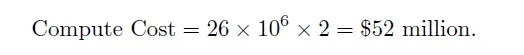
- Human Resources Training a model of this scale required a team of 50 experts, each earning an average annual salary of $500,000. For the project’s duration:
This project duration includes the time when the developers starts with architecture, data engineers cleaning the data. Data mining and many other process over a long period of time. Still this is a very rough estimate of labor cost.
3. Total Cost
The combined cost of compute and human resources was:
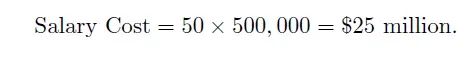
Lessons Learned
The story of LLaMA 3.1 is a reminder of the extraordinary effort behind every AI breakthrough. Here are the key takeaways:
- The Scale of Innovation: Training a model with 405 billion parameters demands a level of infrastructure and expertise that few can achieve.
- Cost-Driven Challenges: Compute costs dominate the budget, making efficiency a critical focus for AI development.
- Collaboration is Key: Achieving such feats requires close collaboration between researchers, engineers, and industry leaders.
Looking Ahead
As technology evolves, the costs of training large models may decrease, but the lessons from LLaMA 3.1 remain clear: innovation requires investment, not just in hardware, but in people, ideas, and ambition.
Next time you use an AI tool, pause for a moment to appreciate the monumental effort behind its creation. These models aren’t just lines of code — they’re the product of human ingenuity, powered by some of the most advanced technology in the world.
Let’s join hands and empower the AI community:
Looking for AI services or consultancies? Checkout our quality services at: https://synbrains.ai
Or connect with me directly at: https://www.linkedin.com/in/anudev-manju-satheesh-218b71175/
Buy me a coffee: https://buymeacoffee.com/anudevmanjusatheesh
LinkedIn community: https://www.linkedin.com/groups/14424396/
WhatsApp community: https://chat.whatsapp.com/ESwoYmD9GmF2eKqEpoWmzG
I truly believe in knowledge sharing and uplifting the community.


