

DeepSeek is a powerful AI model rivaling GPT‑4 with better reasoning, efficiency, and cost‑effectiveness. It uses Mixture of Experts (MoE) for optimized inference, delivering strong performance on logic and language tasks while running at a fraction of the cost and compute of industry-leading models.
The AI landscape is evolving at an unprecedented pace, with new models emerging to challenge established players like OpenAI. One of the most exciting newcomers is DeepSeek, developed by High Flyer, a Chinese AI startup that has introduced groundbreaking models that push the boundaries of cost-efficiency, reasoning, and long-context processing.
DeepSeek has launched two primary models:
DeepSeek V3, a general-purpose AI model comparable to GPT-4o DeepSeek R1, a reasoning-optimized model designed for complex problem-solving, similar to OpenAI o1’s chain-of-thought capabilities. In this article, we’ll break down the architecture of these models, explain key AI concepts such as Mixture of Experts (MoE), tokens, context windows, and model distillation, and compare DeepSeek’s performance with existing AI models.
DeepSeek’s Dual-Model Approach
DeepSeek’s architecture consists of two main models:
1. DeepSeek V3: The Generalist DeepSeek V3 is designed to handle a wide range of AI tasks, from text generation and summarization to translation and programming assistance. However, what makes it stand out is its innovative Mixture of Experts (MoE) architecture, which we’ll explore in detail later.

2. DeepSeek R1: The Advanced Reasoning Model
DeepSeek R1 is optimized for reasoning-based tasks. It follows a chain-of-thought approach, breaking down problems into smaller steps before arriving at a solution. This makes it more accurate in logical, mathematical, and analytical tasks.
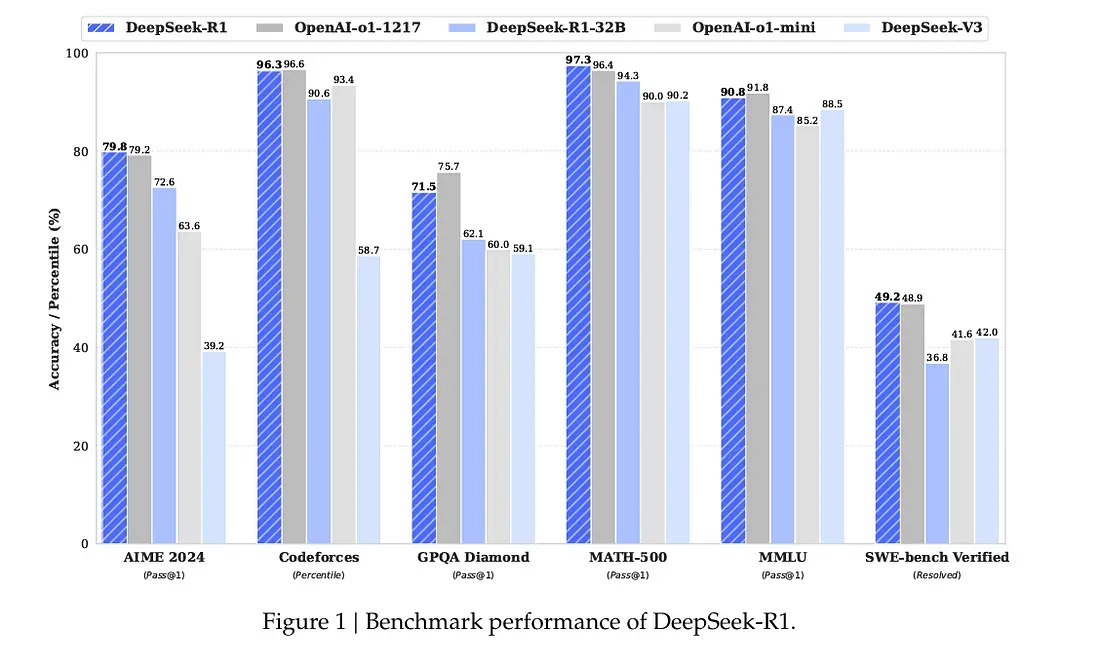
Unlike traditional AI models that process tasks holistically, R1 follows a structured reasoning path, similar to how humans think through problems. This results in higher-quality outputs, especially for complex problem-solving scenarios.
Understanding Key AI Concepts
1. What is a Token in AI?
A token is the basic unit of text that an AI model processes. It can be:
- A word (e.g., “DeepSeek” → 1 token)
- A subword (e.g., “running” → [“run”, “ning”])
- A punctuation mark (e.g., “.” or “,” → 1 token)
- A single character (especially in languages like Chinese)
Example: Sentence : “DeepSeek is revolutionary!” Tokens (for an English model) : [“DeepSeek”, “is”, “revolutionary”, “!”] → 4 tokens.
The number of tokens determines how much information an AI model can process at once.
2. What is a Context Window?
A context window refers to the maximum number of tokens an AI model can process in a single interaction. DeepSeek V3 has a 128,000-token context window, meaning it can read and process the equivalent of an entire book in one session.
Comparison of Context Windows: A larger context window allows AI to remember and analyze long conversations or documents, making it more useful for applications like legal analysis, research, and coding assistance.
Most AI models lose track of earlier inputs in long conversations, but DeepSeek is trained to retain and process large amounts of information seamlessly.
- GPT-3.5: 4,096 tokens (~3 pages of text)
- GPT-4: 32,000 tokens (~25 pages of text)
- DeepSeek V3: 128,000 tokens (~an entire book of around 100 pages)
Why Does Context Window Matter?
A larger context window allows AI to remember and analyze long conversations or documents, making it more useful for applications like legal analysis, research, and coding assistance.
Most AI models lose track of earlier inputs in long conversations, but DeepSeek is trained to retain and process large amounts of information seamlessly.
3. What is the Mixture of Experts (MoE) Model?
DeepSeek V3 uses Mixture of Experts (MoE), a powerful architecture that significantly improves efficiency and scalability.
1. How Traditional AI Models Work (Dense Networks):
Standard AI models use all parameters for every token. This increases computational cost and slows down inference. 2. How MoE Works (Selective Activation):
DeepSeek V3 has 671 billion total parameters, but only 37 billion parameters are activated per token. Instead of using all neurons, MoE selects the most relevant “expert” networks for each task. This improves efficiency, reduces energy consumption, and speeds up processing. MoE Analogy:
Imagine a university with 671 professors.
-
A traditional AI model would consult all 671 professors for every question (wasting time and resources).
-
DeepSeek V3 only consults the 37 most relevant professors per question, making it faster and more efficient. Why is MoE Important?
-
Reduces training costs while maintaining high performance.
-
Scales well to larger datasets without increasing computational demand exponentially.
-
Allows AI to specialize, improving accuracy in various domains.
4. What is Model Distillation?
Model distillation is a technique used to train smaller AI models using a larger, more advanced “teacher” model. DeepSeek R1 serves as a teacher model for training distilled versions of AI, including models based on Qwen and LLaMA.
How Distillation Works:
- A large AI model (DeepSeek R1) generates high-quality responses.
- A smaller AI model is trained to replicate these responses using different methods which includes the use of output logits or text as such.
- The result? A lighter, faster AI model that maintains high accuracy.
Benefits of Model Distillation:
- Enables smaller AI models to perform at near teacher model levels.
- Reduces hardware requirements, making AI accessible on lower-end devices.
- Optimizes AI for mobile applications and edge computing.
Performance Comparison: DeepSeek vs. GPT-4o & Distilled Llama 70b
DeepSeek has been tested against leading AI models in real-world tasks:
Task 1: Number Comparison (9.11 vs. 9.8)
- DeepSeek R1: Correctly identified 9.8 as larger, with detailed reasoning.
- DeepSeek V3: Also provided the correct answer even being a non reasoning model.
- GPT-4o: Incorrectly stated that 9.11 was larger.
- Openai-o1-mini: Correctly stated as 9.8 is larger.
- Deepseek LLaMA 70B — used with groq.com (Distilled Model): Correctly reasoned as 9.8. Key Takeaway: DeepSeek R1 demonstrated reasoning power very similar to OpenAI reasoning models.
Task 2: Building a Splitwise Clone
question = "Give me the html, css and js code to create a small replica
of split wise app. The functionalities should include add people.
Add amount with description and then split based on shares or equally.
The app should have a great UI with promising user experience.
Make sure to give whole code as single html file with css and js within that."
-
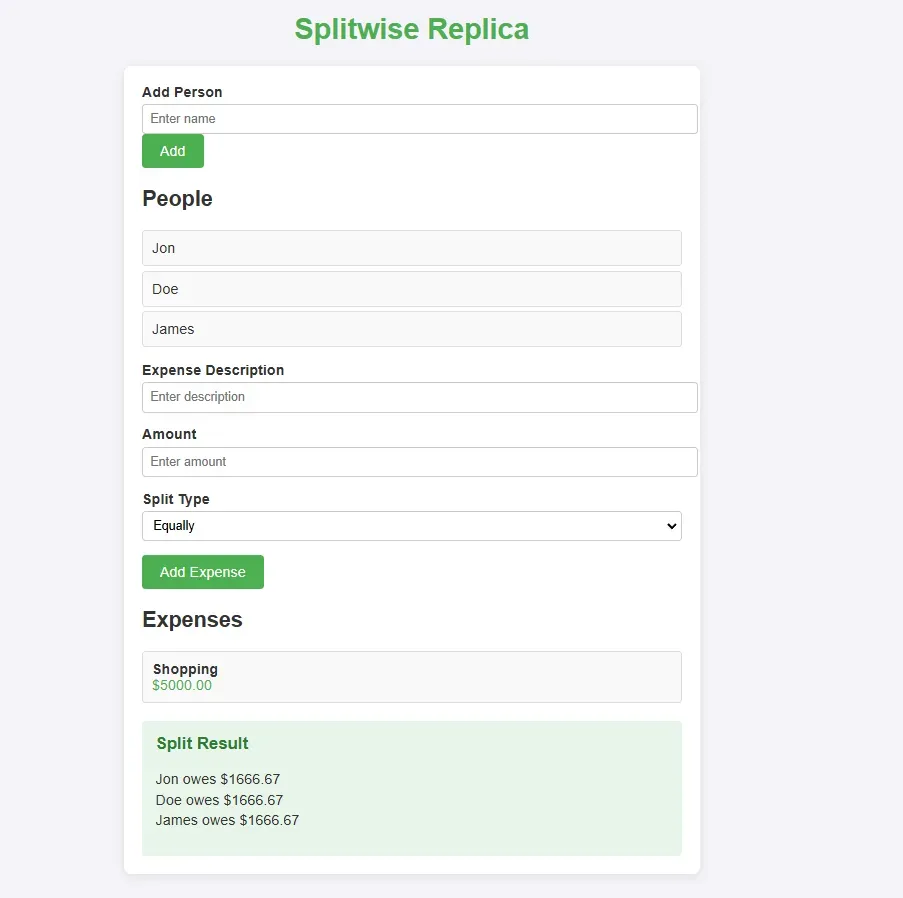
DeepSeek’s V3 version : Provided the most complete solution, including payment tracking and user validation. Not a perfect UI. Calculations are not correct in further testing.
-
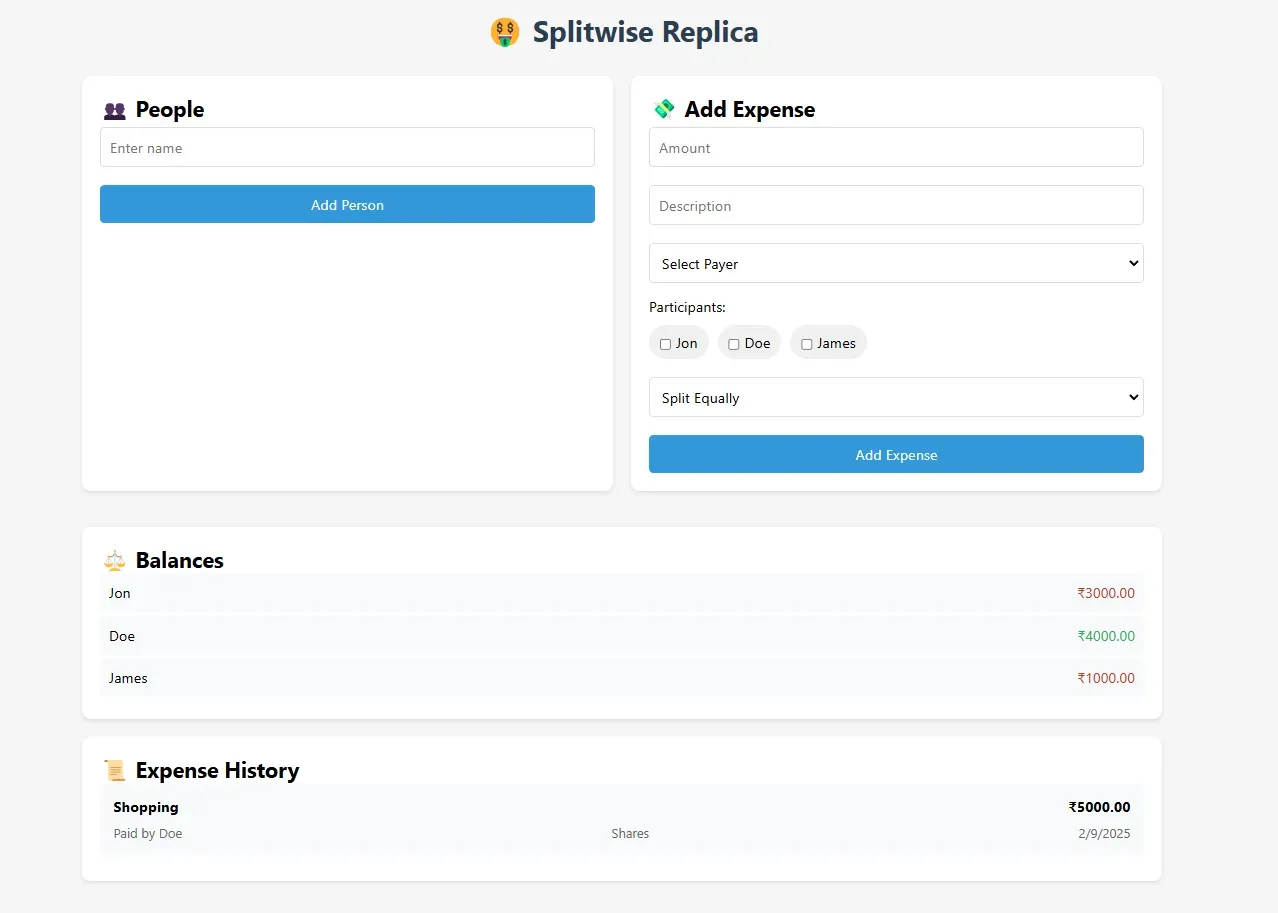
DeepSeek R1 : Took longer but provided more comprehensive functionality and the best output compared to other models. Most comprehensive solution with Balances properly shown and payer was included making it a complete logic.
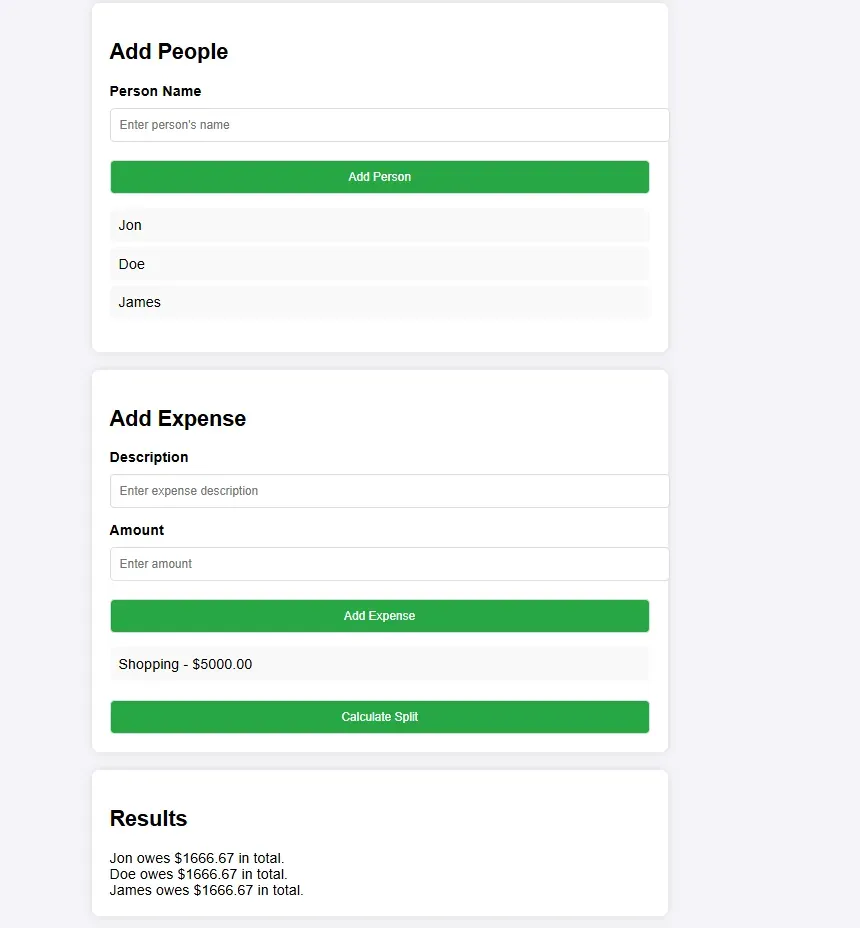
- GPT-4o: Missed some key details. Very long UI.
- Openai-o1-mini: Missed some key details of including the payer and always consideres the first person as the payer.
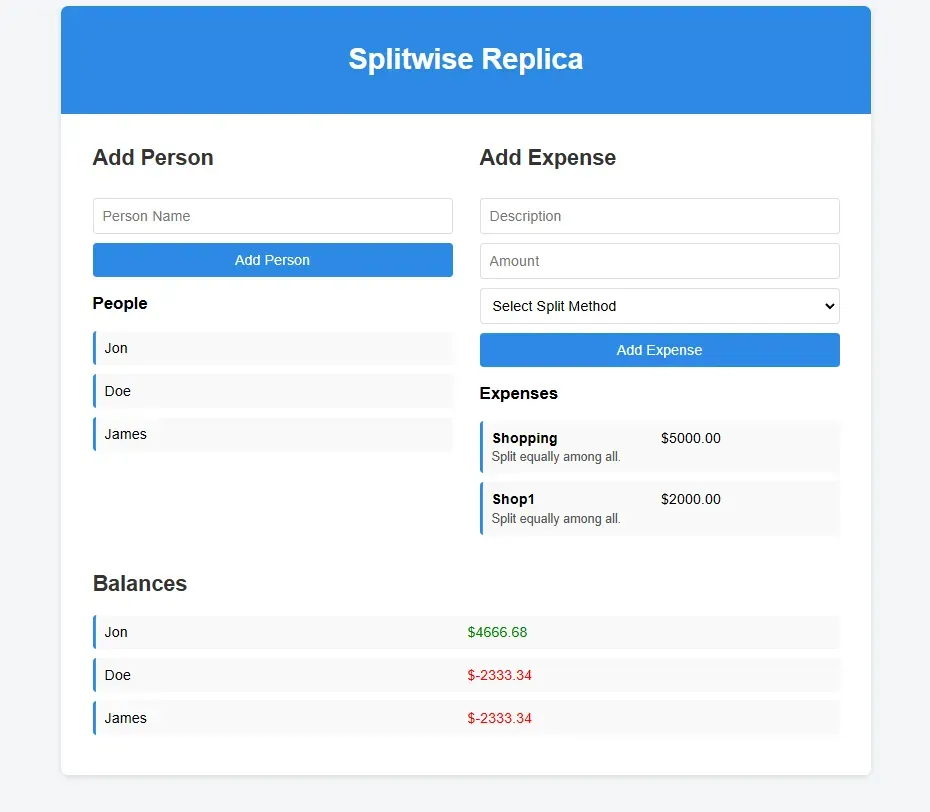
- Deepseek LLaMA 70B (Distilled Model): Performed well, nearly matching o1-mini model.
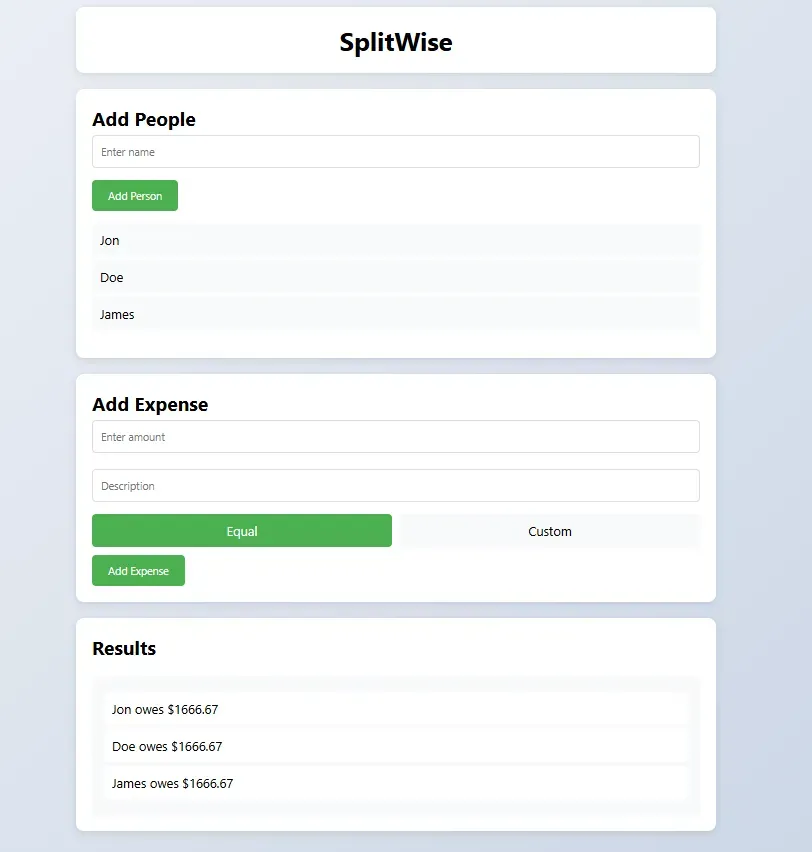
Key Takeaway: DeepSeek R1 had the best quality UI and outputs compared with all the other models.
Market Adoption & Accessibility
DeepSeek’s models are seeing rapid adoption, with:
- 1.15 million+ downloads for DeepSeek V3 until February 2025
- 2.15 million+ downloads for DeepSeek R1 until February 2025 -(Huggingface Downloads)
How to Access DeepSeek
- Open-Source Models: Available on Hugging Face under an MIT license. : https://huggingface.co/deepseek-ai
- API Access: OpenAI-compatible API, supporting Python and cURL requests. : https://api-docs.deepseek.com/
- Groq UI or API: For fast inferencing of Deepseek 70b distill model. : https://groq.com/
Final Thoughts: Why DeepSeek is a Game-Changer
DeepSeek is challenging OpenAI and other major players with its cost-efficient, high-performance AI models.
Why DeepSeek Stands Out:
- Superior Reasoning: Competitive with Openai reasoning models.
- Mixture of Experts (MoE): Faster, more efficient processing.
- 128,000-token Context Window: Handles long documents effortlessly.
- Cost-Effective: Trained at just $5.6 million, far cheaper than any proprietary model.
TL;DR
DeepSeek is a powerful AI model rivaling GPT-4 with better reasoning, efficiency, and cost-effectiveness. It uses Mixture of Experts (MoE) for faster processing, supports a 128K-token context window, and outperforms GPT-4 in logical tasks. Open-source and cheaper to train, DeepSeek is reshaping AI innovation.
Deepseek V3 Technical report: https://arxiv.org/pdf/2412.19437v1
Deepseek R1 Technical report: https://arxiv.org/pdf/2501.12948
Huggingface : https://huggingface.co/deepseek-ai
Let’s join hands and empower the AI community:
Looking for AI services or consultancies? Checkout our AI services at: https://synbrains.ai
Or connect with me directly at: https://www.linkedin.com/in/anudev-manju-satheesh-218b71175/
Buy me a coffee: https://buymeacoffee.com/anudevmanjusatheesh
LinkedIn community: https://www.linkedin.com/groups/14424396/
WhatsApp community: https://chat.whatsapp.com/ESwoYmD9GmF2eKqEpoWmzG

